我喜欢在闲暇时间阅读一本好书,尤其是手捧一杯香浓的咖啡。我尤其喜欢逛书店,浏览书架,发现意想不到的读物。在一次逛书店的过程中,我发现了一本书,这本书立刻引起了我的注意:
预测机器 作者:Ajay Agrawal、Joshua Gans 和 Avi Goldfarb。
老实说,你能说出一个现在对人工智能/移动语言至少没有一点好奇心的人吗?作者在书中解释了 “人工智能的简单经济学,并介绍了如何将该技术用于点解决方案”。 .在该书的一个章节中,以下内容令我印象深刻:
有了更好的预测,我们就有更多机会考虑各种行动的回报,换句话说,我们就有更多机会做出判断。这意味着,更好、更快、更便宜的预测会给我们带来更多的决策。
虽然本书的重点是人工智能和机器学习,但这句话引起了我的共鸣,因为同样的想法也适用于工程模拟领域,尤其是 CFD。无论模拟的目的如何,能够更快、更明智地做出设计决策对工程师来说都至关重要。创新和保持竞争力的压力只会加剧对提高生产率和加速仿真工作流程的需求。
此外,由于工程师希望尽可能多地包含物理真实感和几何细节,因此创建高保真数字孪生模型的需求也在不断增加。因此,快速网格划分是一项具有战略意义的辅助工具,可带来竞争优势,使工程师能够加快产品开发,更快地将产品推向市场。为了支持这一目标,我们努力寻求能够加快 CFD 工作流程的解决方案,使您能够快速评估众多设计变体。对于网格划分来说,这可能涉及到从优化单个工作流程到消息传递接口(MPI)分布式内存并行化的方方面面,即在多个 CPU 上同时执行网格划分任务的能力。
在本博客中,我们将探讨 Simcenter STAR-CCM+ 的最新增强功能如何提高了网格划分性能,使工程师能够提高仿真吞吐量并更快地洞察问题。
利用 MPI 表面包加速几何清理 Simcenter STAR-CCM+ 的主要优势之一是从 CAD 到解决方案的流水线工作流程,使工程师能够处理复杂的几何图形。许多仿真工作流程都涉及包含数以万计零件的庞大 CAD 装配。这些 CAD 文件通常包括非常大的装配体和 “脏 “几何体。所谓 “脏”,是指输入的几何图形可能存在孔洞、交叉、需要剔除、包含重叠和/或非曲面顶点或边缘。手动清理和修复此类几何图形是一个劳动密集型过程,可能需要数天甚至数周才能完成。
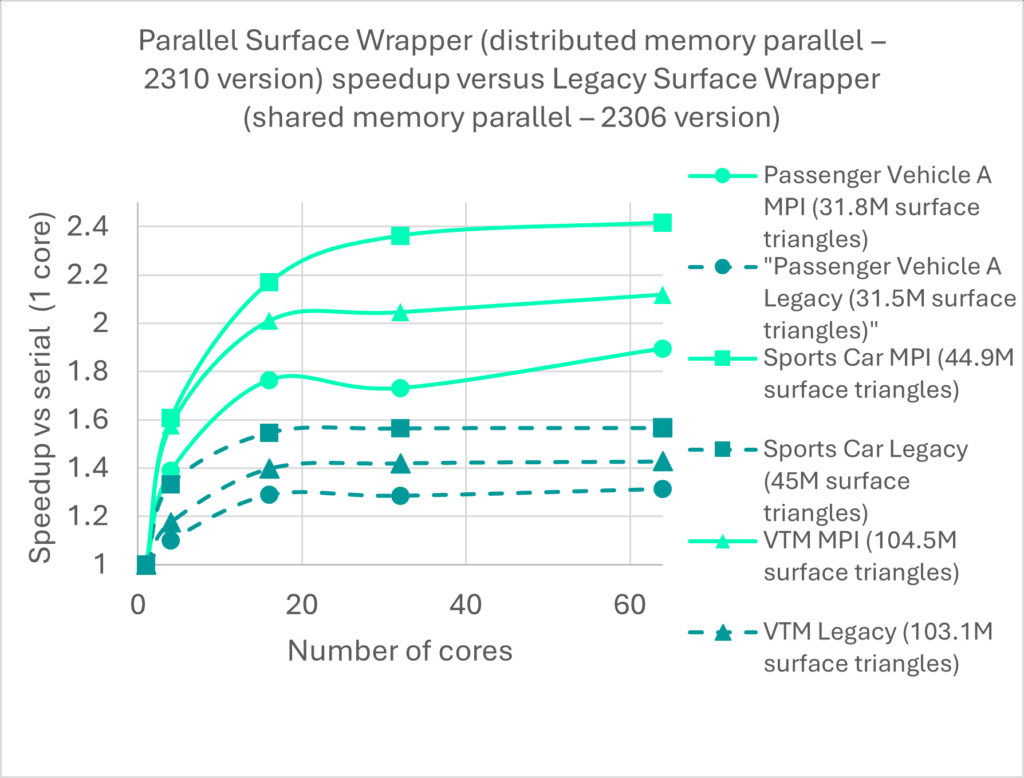
在 Simcenter STAR-CCM+ 中为网格划分准备几何体的关键工具之一是 “曲面包围器”。曲面包裹器可以处理任何任意复杂的 CAD 或网格零件,并生成不漏水的流形曲面。它的工作原理是在离散几何体上有效地 “收缩包裹 “一个高质量的三角形曲面网格。其主要优势之一是能够准确保留锐边和锐角等几何特征。在 Simcenter STAR-CCM+ 2310 版本中,我们推出了首个 MPI 并行版本的曲面包围器,与共享内存并行版本(也称为 “传统包围器”)相比,性能有了显著提高。在第一个版本中,我们证明与传统封装器相比,封装时间最多可缩短 43%。
图 1:MPI 表面封装器第一阶段,2310 版本 然而,对于超大型案例来说,这种性能提升还远远不够,为了履行我们不断改进的承诺,在 Simcenter STAR-CCM+ 2510 版本中,我们将发布 MPI 曲面封装器的第二阶段。让我们来看看性能方面的改进。
如图 2 所示,与版本 2506(MPI 曲面包装器第一阶段)相比,版本 2510 中的 MPI 曲面包装器性能提高了约 2 倍。与传统封装器相比,速度提高了 5.6 倍。对于复杂的几何体,如科尔维特汽车,其总体积网格数为 9,300 万个单元,在 32 个内核(英特尔®至强® Gold 6442Y)上对整个几何体进行包覆仅需 6.5 分钟。
图 2:MPI 表面封装器第二阶段 如何封装更大的案例?在 Corvette 案例中,曲面包装器生成了 3740 万个三角形曲面。相比之下,如下图所示的玛莎拉蒂 Ghibli 车箱要大得多,只需要 9 分钟就能完成 5630 万个三角形的包裹,最终生成 1.42 亿个单元的体积网格。
确保网格一致性 如前所述,速度是一个关键属性,但结果的一致性对于确保仿真结果的可信度同样重要。我们的目标是在软件版本和不同内核数之间保持一致。
在广泛的测试中,最终曲面三角形的变化小于 1%。具体来说,对于下图所示的科尔维特几何图形,2506 和 2510 版本的最终曲面三角形数量差异仅为 0.005%。在 2510 版本中,在使用 1、32 和 48 个处理器的三次运行中,与串行执行相比,差异仅为 0.06%。
曲面封装结果的这种一致性意味着后续的重合曲面和生成的体积网格也将保持一致。
表面重定向性能增强,网格划分速度更快 MPI 曲面包围器可显著提高性能,并加快应用它的工作流程。然而,曲面网格划分仍然耗时,这取决于几何形状。在 2506 版本中,我们对曲面重置器进行了改进,执行时间最多可缩短 40%。不过,这取决于案例的复杂性和输入 CAD 的质量。
例如,与不需要运行曲面包围器的 DrivAer 几何案例(体积网格中的单元格数为 8.55 亿)相比,Corvette 几何案例(体积网格中的单元格数为 9 300 万)涉及的几何输入较少。这意味着,如果我选择这样的曲面网格设置来为 Corvette 建立接近 855M 单元的体 积网格,整个过程将大大延长。这突出了在评估网格算法性能时上下文的重要性。
图 3:2502 和 2506 版本的表面重力测量时间比较 通过改进算法和硬件优化网格划分性能 Simcenter STAR-CCM+ 产品战略的一个关键部分是提高包括网格划分在内的每种算法的性能。我们的产品开发团队致力于实现这一目标。不过,网格划分性能不仅与所使用的算法或模型大小有关。例如,在不需要网格细化的地方过度细化网格会对任何 CFD 模拟的周转时间产生负面影响。
尽管如此,让我来告诉您另一个会显著影响仿真吞吐量的因素:所使用的硬件。
我将比较两款不同的 AMD 处理器,评估使用单核心生成曲面网格所需的时间(因为 Simcenter STAR-CCM+ 中的曲面汇集器目前以串行模式运行)。所涉及的处理器是 AMD EPYC 7532 Rome 和 AMD EPYC 9755 Turin(幸运的是,一些同事慷慨地为我提供了一台新机器,正好赶上这次测试!)。我将为 DrivAer 和玛莎拉蒂 Ghibli 的几何图形创建一个曲面网格。
您会将赌注押在哪款处理器上?
如下图所示,AMD EPYC 9755 Turin 的性能超过了它的老表(年轻了 4 岁零几个月),曲面网格划分速度提高了 1.9 倍。然而,正如我们之前讨论过的,在评估网格划分性能时,上下文是关键,这就是为什么输入几何体简单得多的曲面网格划分所需的时间(无论最终体积网格数多少)比 Ghibli 案例(在曲面重网格之前需要运行曲面封装器)要少得多的原因。两个案例都使用相同版本的软件(Simcenter STAR-CCM+ 2510)进行曲面网格划分,但在两台不同的机器上进行。
即使没有并行性,较新的处理器生成网格的速度也明显更快。这主要是因为曲面网格生成受内存带宽限制。这意味着其性能较少取决于时钟速度,而更多取决于从内存传输数据的速度。AMD EPYC 9755 Turin 具有更大、更高效的 L1/L2/L3 高速缓存结构,与 AMD EPYC 7532 Rome 使用的 DDR4 相比,支持带宽更高、延迟更低的 DDR5 内存。值得注意的是,其他网格器也将从更新的硬件中获益,不过性能提升的程度会因涉及的网格器和机箱复杂程度而有所不同。
图 4:不同处理器的曲面网格时间比较 以快速 CFD 表面包覆和更快的表面网格划分推动创新 网格划分性能对 CFD 仿真至关重要,它能推动各行各业的创新。Simcenter STAR-CCM+ 2510 中的 CFD 曲面包裹技术的发展标志着仿真工程师的重大飞跃。通过进一步利用 MPI 并行化的强大功能,最新的曲面包装器提供了快速、可靠和可扩展的网格划分功能,即使是最复杂和最 “脏 “的几何形状也不例外。这些进步意味着工程师可以减少清理 CAD 和等待网格的时间,从而可以更专注于探索设计空间,更快、更自信地做出更多设计决策。
在我们为让您更快地做出更好的预测而不断进取的同时,我读到 Ajay Agrawal 说道:”我们的目标是让您更快地做出更好的预测:
更好的预测会提升判断的价值。毕竟,如果你不知道自己有多喜欢保持干燥或有多讨厌带伞,那么知道下雨的可能性也无济于事。
这是对所有工程师的呼吁:无论是人工智能/ML 还是基于物理的仿真,预测更快、更容易生成的事实使我们的核心责任是花更多时间根据这些预测做出正确的判断。
请继续关注,探索 Simcenter STAR-CCM+ 2510 中更多令人兴奋的新功能!
源链接